




Overview
I am currently an Associate Professor of Political Science at Purdue University. I am also a Research Scholar at the Center for C-SPAN Scholarship & Engagement. Previously, I was an Assistant Professor of Social Science Informatics at the University of Iowa and a postdoctoral research fellow at Harvard's Kennedy School and Northeastern University.
My research uses novel quantitative, automated, and machine learning methods to analyze non-traditional data sources such as audio (or speech) data and video data. I use these to understand the causes and consequences of non-verbal political behavior, such as vocal inflections and walking trajectories, especially in relation to descriptive representation and implicit gender/racial bias. Underlying my research is a love for high-performance computing and a genuine desire to make "big data" more accessible, while my substantive interests are firmly grounded in American political behavior at both the mass- and elite-level.
Text Analysis
Words are spoken, not written. Most of my work using political texts emphasizes this point. For example, the word cloud you see above is from Democratic speeches delivered in the 111th and 112th U.S. House of Representatives. Unlike others, this word cloud is weighted by the speaker's vocal inflections (e.g., amplitude and pitch). Such an approach emphasizes the intersection between text and audio data. Even though they are not shown here, I have made similar calculations using video-based measures.
Audio Analysis
Like you and I, political elites are emotional beings. Whether it is Joe Wilson (R-SC) yelling “You Lie!” at President Obama or the late Antonin Scalia raising his tone during oral arguments, many elites seem to wear their hearts on their sleeves. In order to answer these questions, this research program introduces large-n audio analysis to political science. Using R, Python, and Perl, I scraped text and audio from close to 75,000 floor speeches found on House Video Archives. This project won the University of Illinois’ Kathleen L. Burkholder Prize for best dissertation in Political Science. My article with Matthew Hayes and Diana O'Brien recently published in the American Political Science Review provides the most recent example of this work.
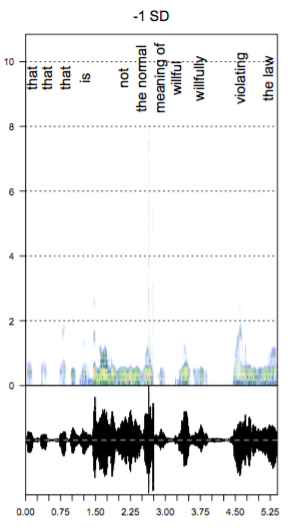
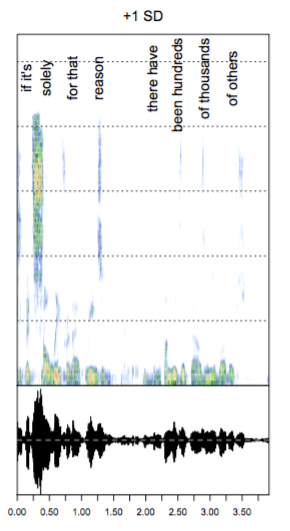
My work with Maya Sen and Ryan Enos is a continuation of my work in this area. Using audio data from over 240,000 questions and comments delivered during oral arguments between 1981-2014 we explore emotional expression on the Supreme Court. The figures to the left (not emotionally activated) and right (emotionally activated) are from this work. Both are samples of audio from Justice Scalia. Yellow and red areas indicate higher amplitude. The vocal pitch is shown at the bottom. Our first paper is now published in Political Analysis.
Video Analysis
We are surrounded by videos. 500 hours of video is uploaded to YouTube every minute. There are an estimated 30 million surveillance cameras in the United States shooting 4 billion hours of video a week. The C-SPAN video library has 221,898 hours of video and counting. Using computer vision techniques, I use these videos to understand behavior inside and outside Captiol Hill.
In my paper, "Using Motion Detection to Measure Social Polarization in the U.S. House of Representatives," I use computer vision techniques to understand the degree to which Democrats and Republicans talk to one another on the House floor. Using 6,526 C-SPAN videos and OpenCV, I find members of Congress are increasingly less likely to literally cross the aisle. This project has received grant support from C-SPAN and was recently covered by the Washington Post.